You must have a publicly accessible OpenAI-compatible chat completions endpoint before proceeding with deployment.
When to use custom LLM providers
Custom LLM providers are ideal for scenarios where you need:- Specific model requirements - Access to proprietary models, fine-tuned models, or the latest releases not yet available through standard providers.
- Data residency and compliance - Ensure your data stays within specific geographic regions or private cloud environments.
- Cost optimization - Leverage enterprise agreements, reserved capacity, or self-hosted infrastructure for better economics at scale.
- Advanced model control - Fine-tune parameters, adjust inference settings, or use specialized configurations for your use case.
Azure
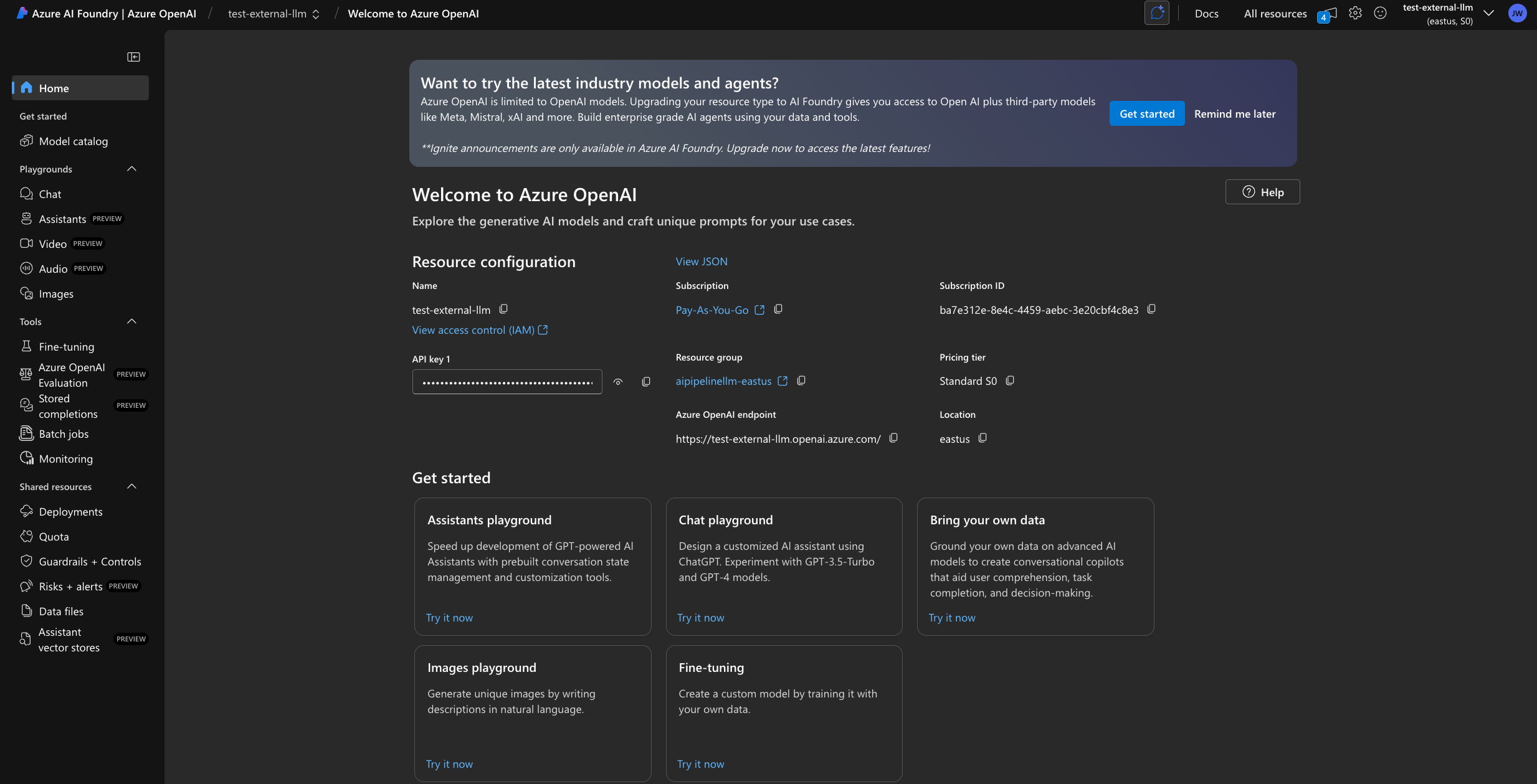
For this guide, we will deploy gpt-4o on Azure AI Foundry. First, create or select a resource.
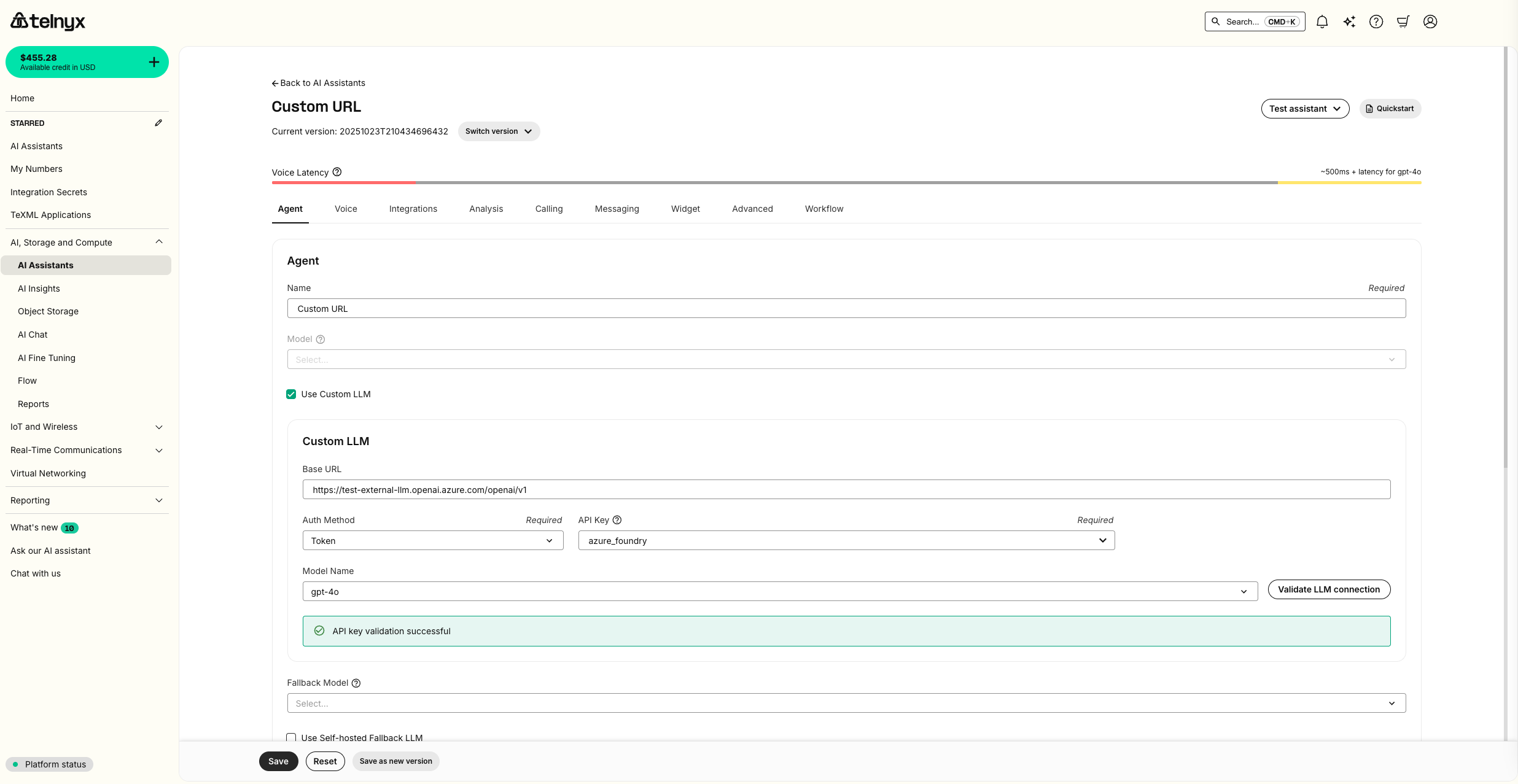
Agent tab, check Use Custom LLM.
Input the endpoint URL as the Base URL and append /openai/v1 and create a new Integration Secret with your API Key.
You will see a dropdown of all possible Azure models but only ones that you have deployed will validate an LLM connection.
Test Assistant dropdown.
Forward metadata to your custom LLM
By default, Telnyx does not include your assistant’s dynamic variables in requests to a custom LLM endpoint. If your model gateway or application needs those values, enableforward_metadata on the assistant’s external_llm configuration.
forward_metadata is true, Telnyx adds a top-level extra_metadata object to the OpenAI-compatible chat completions request body sent to your custom LLM endpoint when dynamic variables are available. The field defaults to false when omitted.
extra_metadata is separate from OpenAI’s native metadata field, so your endpoint must explicitly read extra_metadata from the request body.
Baseten
For this guide, we will deploy Llama 3.3 70B on Baseten. First, clickDeploy Now.
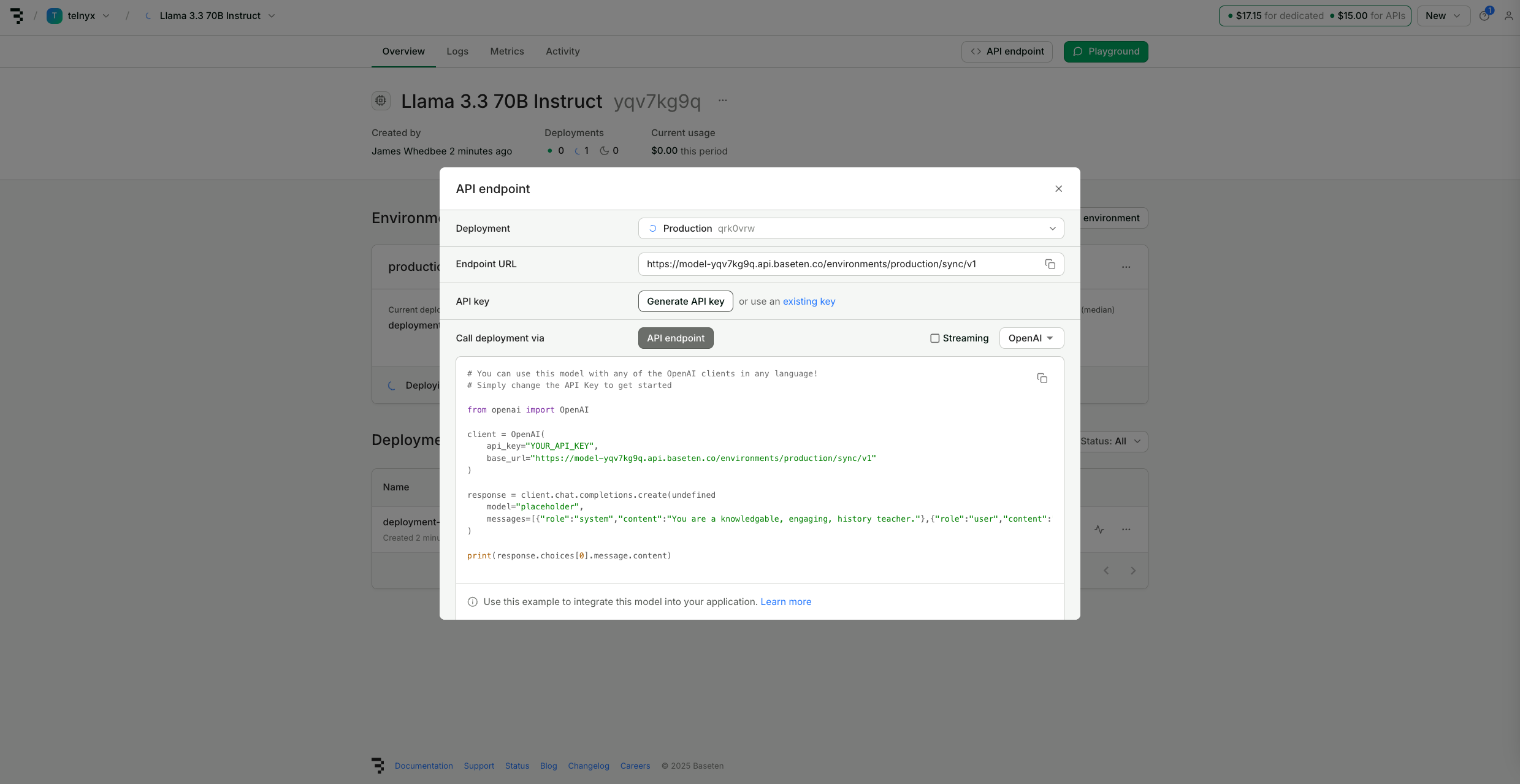
Agent tab, check Use Custom LLM.
Input the Baseten Endpoint URL for your deployment as the Base URL and create a new Integration Secret with your Baseten API Key.
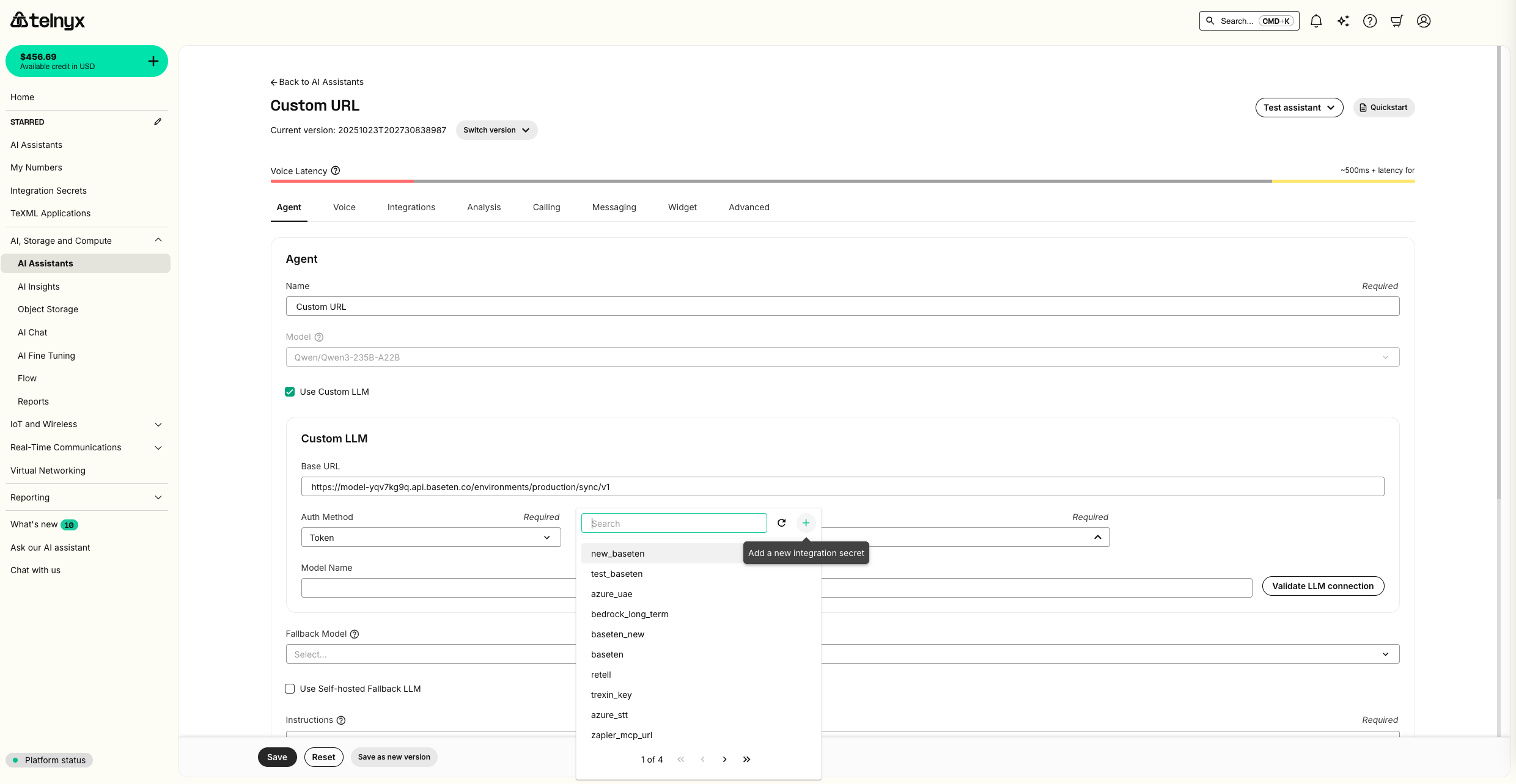
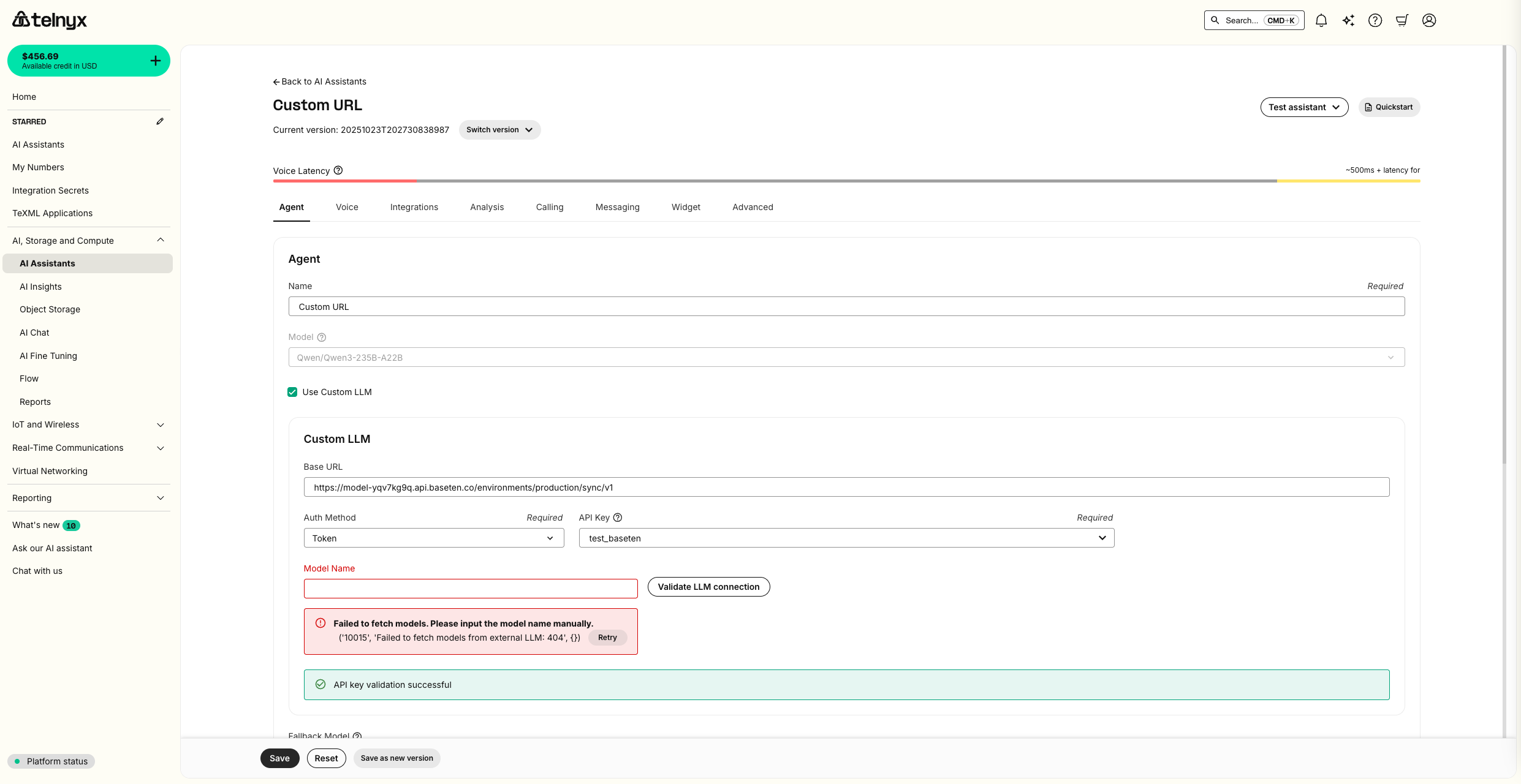
Test Assistant dropdown as well as review metrics in your Baseten deployment.